 Sarakhon Report
Sarakhon Report 
সারাক্ষণ ডেস্ক
১৯৫৬ সালের গ্রীষ্মে নিউ হ্যাম্পশায়ারের ডার্টমাউথ কলেজে একটি ছোট কিন্তু বিখ্যাত দল জড়ো হয়েছিল; এতে তথ্য তত্ত্বের প্রবর্তক ক্লড শ্যানন এবং অর্থনীতিতে নোবেল মেমোরিয়াল পুরস্কার এবং অ্যাসোসিয়েশন ফর কম্পিউটিং মেশিনারির তরিং পুরস্কার উভয়ই বিজয়ী হার্ব সাইমন অন্তর্ভুক্ত ছিলেন। তাদের একত্রিত করেছিলেন একজন তরুণ গবেষক, জন ম্যাককার্থি, যিনি “কিভাবে মেশিনকে ভাষা ব্যবহার করতে, বিমূর্ততা এবং ধারণা গঠন করতে” এবং “এখন মানুষের জন্য সংরক্ষিত সমস্যার সমাধান করতে” চেয়েছিলেন সে সম্পর্কে আলোচনা করতে চেয়েছিলেন। এটি ছিল প্রথম একাডেমিক সমাবেশ যা ম্যাককার্থি “কৃত্রিম বুদ্ধিমত্তা” নামে পরিচিত। এবং এটি পরবর্তী ৬০ বছর ধরে কোনো অগ্রগতি না করে তার উচ্চাকাঙ্ক্ষার সাথে সামঞ্জস্য রেখে একটি টেমপ্লেট সেট করেছিল।

ডার্টমাউথের বৈঠকটি মানুষের মতো চিন্তা করতে পারে এমন মেশিনগুলির প্রতি বৈজ্ঞানিক অনুসন্ধানের সূচনা চিহ্নিত করেনি। অ্যালান টুরিং, যার নামে টুরিং পুরস্কার রাখা হয়েছে, এটি সম্পর্কে ভেবেছিলেন; তাই জন ভন নিউম্যানও, যিনি ম্যাককার্থির জন্য অনুপ্রেরণা ছিলেন।
১৯৫৬ সালের মধ্যে এই বিষয়ে ইতিমধ্যেই বেশ কয়েকটি পদ্ধতি ছিল; ঐতিহাসিকরা মনে করেন যে ম্যাককার্থি তার প্রকল্পের জন্য কৃত্রিম বুদ্ধিমত্তা, পরে AI, শব্দটি তৈরি করেছিলেন তার একটি কারণ হল এটি তাদের সবাইকে অন্তর্ভুক্ত করার জন্য যথেষ্ট বিস্তৃত ছিল, কোনটি সেরা হতে পারে সে প্রশ্নটি উন্মুক্ত রেখে।
কিছু গবেষক এমন সিস্টেমগুলিকে সমর্থন করেছিলেন যা জ্যামিতি এবং প্রতীকী যুক্তির স্বতঃসিদ্ধগুলির মতো বিশ্ব সম্পর্কে সত্যগুলি একত্রিত করার উপর ভিত্তি করে উপযুক্ত প্রতিক্রিয়া নির্ণয় করেছিল; অন্যরা এমন সিস্টেম তৈরি করতে পছন্দ করেছিল যেখানে এক জিনিসের সম্ভাব্যতা অনেকগুলির ক্রমাগত আপডেট হওয়া সম্ভাবনার উপর নির্ভর করত।

পরবর্তী কয়েক দশক এই বিষয়ে প্রচুর বুদ্ধিবৃত্তিক উত্তেজনা এবং বিতর্ক দেখেছিল, কিন্তু ১৯৮০ এর দশকের মধ্যে এগিয়ে যাওয়ার উপায় সম্পর্কে ব্যাপকভাবে সম্মত ছিল: “বিশেষজ্ঞ সিস্টেম” যা মানব দক্ষতার সেরাটিকে ধারণ এবং প্রয়োগ করতে প্রতীকী যুক্তি ব্যবহার করেছিল।
জাপানি সরকার বিশেষ করে এমন সিস্টেম এবং তাদের প্রয়োজনীয় হার্ডওয়্যার ধারণার পিছনে ওজন ছুড়ে দিয়েছিল। কিন্তু বেশিভাগ ক্ষেত্রেই এমন সিস্টেমগুলি বাস্তব বিশ্বের বিশৃঙ্খলার সাথে সামঞ্জস্য করার জন্য খুবই অমার্জনীয় প্রমাণিত হয়েছিল।
১৯৮০ এর দশকের শেষের দিকে AI খারাপ খ্যাতিতে পড়েছিল । তারা এই অবস্থা থেকে উত্তরণ ঘটাতে শুরু করেছিলেন। আজকের উত্থানটি সেই অধ্যবসায়ের একটি পকেট থেকে জন্মেছিল।

১৯৪০ এর দশকে মস্তিষ্কের কোষের এক ধরনের নিউরন কীভাবে কাজ করে তার মৌলিক বিষয়গুলি একত্রিত হওয়ার সাথে সাথে, কম্পিউটার বিজ্ঞানীরা ভাবতে শুরু করেছিলেন যে মেশিনগুলি একইভাবে তারযুক্ত করা যেতে পারে কিনা। একটি জৈবিক মস্তিষ্কে নিউরনের মধ্যে সংযোগ রয়েছে যা একটির ক্রিয়াকলাপকে অন্যটির ক্রিয়াকলাপকে ট্রিগার বা দমন করতে দেয়; একটি নিউরন কি করে তা নির্ভর করে অন্য সংযুক্ত নিউরনগুলি কি করছে তার উপর।
পরীক্ষাগারে এটি মডেল করার প্রথম প্রচেষ্টা (ডার্টফোর্ডের একজন উপস্থিত মারভিন মিনস্কি দ্বারা) নিউরনের নেটওয়ার্কগুলিকে মডেল করতে হার্ডওয়্যার ব্যবহার করেছিল। তখন থেকে, আন্তঃসংযোগ নিউরনের স্তরগুলি সফ্টওয়্যারে অনুকরণ করা হয়েছে।
এই কৃত্রিম নিউরাল নেটওয়ার্কগুলি স্পষ্ট নিয়ম ব্যবহার করে প্রোগ্রাম করা হয় না; পরিবর্তে, তারা প্রচুর উদাহরণের সংস্পর্শে এসে “শেখে”। এই প্রশিক্ষণের সময় নিউরনের মধ্যে সংযোগের শক্তি (“ওজন” হিসাবে পরিচিত) বারবার সামঞ্জস্য করা হয় যাতে, অবশেষে, একটি প্রদত্ত ইনপুট একটি উপযুক্ত আউটপুট তৈরি করে। মিনস্কি নিজেই ধারণাটি পরিত্যাগ করেছিলেন, তবে অন্যরা এটি এগিয়ে নিয়ে গিয়েছিল।

১৯৯০ এর দশকের শুরুর দিকে নিউরাল নেটওয়ার্কগুলি হস্তলিখিত সংখ্যা স্বীকৃতি দিয়ে পোস্ট সাজানোর মতো কাজগুলি করতে প্রশিক্ষিত হয়েছিল। গবেষকরা ভেবেছিলেন যে আরও নিউরনের স্তর যুক্ত করলে আরও পরিশীলিত অর্জন সম্ভব হতে পারে। কিন্তু এটি সিস্টেমগুলিকে আরও ধীরে চলতে বাধ্য করেছিল। একটি নতুন ধরণের কম্পিউটার হার্ডওয়্যার সমস্যাটির চারপাশে একটি উপায় সরবরাহ করেছিল।
এর সম্ভাবনা ২০০৯ সালে নাটকীয়ভাবে প্রদর্শিত হয়েছিল, যখন স্ট্যানফোর্ড ইউনিভার্সিটির গবেষকরা তাদের রুমে একটি গেমিং পিসি ব্যবহার করে একটি নিউরাল নেট চালানোর গতি ৭০ গুণ বাড়িয়ে দিয়েছিল। এটি সম্ভব হয়েছিল কারণ, সমস্ত পিসিতে পাওয়া “কেন্দ্রীয় প্রসেসিং ইউনিট” (সিপিইউ) ছাড়াও, এতে একটি “গ্রাফিক্স প্রসেসিং ইউনিট” (জিপিইউ) ও ছিল যা স্ক্রীনে গেমের জগৎ তৈরি করেছিল।
এবং জিপিইউ নিউরাল-নেটওয়ার্ক কোড চালানোর উপায়ে ডিজাইন করা হয়েছিল। সেই হার্ডওয়্যার গতি বাড়ানোর সাথে আরও দক্ষ প্রশিক্ষণ অ্যালগরিদমগুলিকে একত্রিত করে মানে কয়েক মিলিয়ন সংযোগ সহ নেটওয়ার্কগুলি যুক্তিসঙ্গত সময়ে প্রশিক্ষিত হতে পারে; নিউরাল নেটওয়ার্কগুলি বড় ইনপুটগুলি পরিচালনা করতে পারে এবং, গুরুত্বপূর্ণভাবে, আরও স্তরগুলি দেওয়া যেতে পারে। এই “গভীর” নেটওয়ার্কগুলি অনেক বেশি সক্ষম বলে প্রমাণিত হয়েছিল।
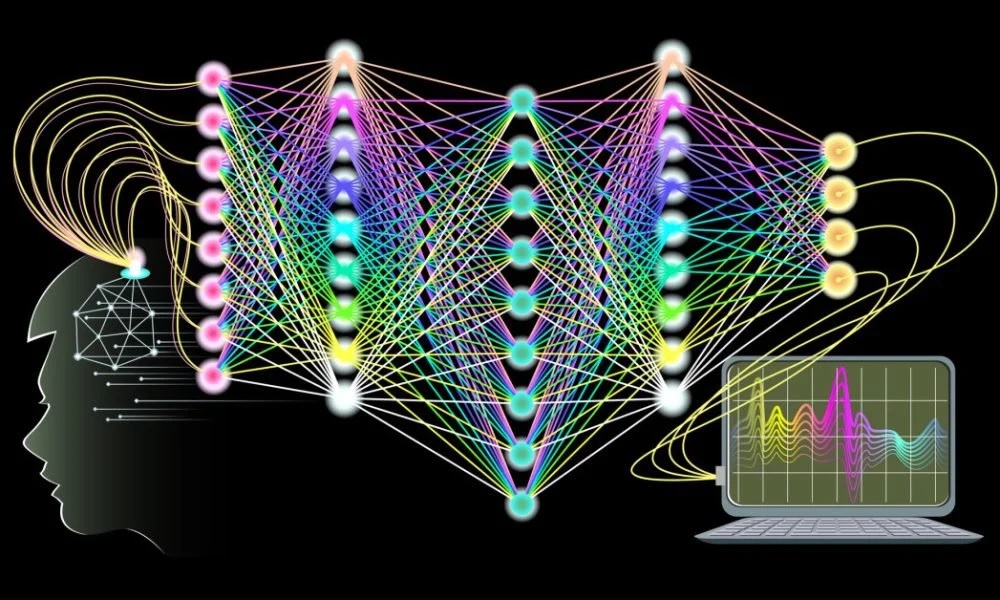
এই নতুন পদ্ধতির শক্তি, যা “গভীর শিক্ষা” নামে পরিচিত ছিল, এটি ২০১২ সালের ইমেজনেট চ্যালেঞ্জে স্পষ্ট হয়েছিল। চ্যালেঞ্জে প্রতিদ্বন্দ্বিতাকারী চিত্র-স্বীকৃতি সিস্টেমগুলিকে এক মিলিয়নেরও বেশি লেবেলযুক্ত চিত্র ফাইলের একটি ডেটাবেস প্রদান করা হয়েছিল। যে কোনো প্রদত্ত শব্দের জন্য, যেমন “কুকুর” বা “বিড়াল”, ডেটাবেসে কয়েকশত ছবি ছিল।
চিত্র-স্বীকৃতি সিস্টেমগুলি এই উদাহরণগুলি ব্যবহার করে ইনপুটকে, চিত্রের আকারে, আউটপুটের সাথে একশব্দের বর্ণনার আকারে “মানচিত্র” করতে প্রশিক্ষিত হবে। তারপরে সিস্টেমগুলিকে পূর্বে দেখা যায়নি এমন পরীক্ষার চিত্রগুলিকে খাওয়ানোর সময় এমন বর্ণনা তৈরি করার চ্যালেঞ্জ দেওয়া হয়েছিল। ২০১২ সালে, জিওফ হিন্টনের নেতৃত্বে একটি দল, তখন টরন্টো বিশ্ববিদ্যালয়ে, ৮৫% নির্ভুলতা অর্জনের জন্য গভীর শিক্ষা ব্যবহার করেছিল।
এটি একটি সাফল্য হিসাবে তাত্ক্ষণিকভাবে স্বীকৃত হয়েছিল। ২০১৫ সালের মধ্যে ইমেজ-স্বীকৃতি ক্ষেত্রে প্রায় সবাই গভীর শেখার ব্যবহার করছিল, এবং ইমেজনেট চ্যালেঞ্জে বিজয়ী নির্ভুলতা ৯৬% এ পৌঁছেছিল — গড় মানব স্কোরের চেয়ে ভাল। গভীর শেখা অন্যান্য অনেক “মানুষের জন্য সংরক্ষিত সমস্যাগুলির” জন্যও প্রয়োগ করা হচ্ছিল যা এক ধরণের জিনিসকে অন্যটির সাথে মানচিত্রে কমানো যেতে পারে: বক্তৃতা স্বীকৃতি (ধ্বনি থেকে পাঠ্য), মুখের স্বীকৃতি (মুখের নামের সাথে মানচিত্র করা) এবং অনুবাদ।

এই সমস্ত অ্যাপ্লিকেশনগুলিতে ইন্টারনেটের মাধ্যমে অ্যাক্সেস করা বিশাল পরিমাণে ডেটা সাফল্যের জন্য গুরুত্বপূর্ণ ছিল; এর মানে হল যে বাজারগুলি বড় হওয়ার সম্ভাবনার কথা বলে ইন্টারনেট ব্যবহারকারীর সংখ্যা। এবং নেটওয়ার্কগুলি যত বড় (অর্থাৎ গভীর) করা হয়েছিল এবং তাদের যত বেশি প্রশিক্ষণের ডেটা দেওয়া হয়েছিল, তাদের কর্মক্ষমতা ততই উন্নত হয়েছিল।
গভীর শেখা শীঘ্রই সমস্ত ধরণের নতুন পণ্য এবং পরিষেবাগুলিতে স্থাপন করা হচ্ছিল। আমাজনের অ্যালেক্সার মতো ভয়েস-চালিত ডিভাইসগুলি উপস্থিত হয়েছিল। অনলাইন ট্রান্সক্রিপশন পরিষেবাগুলি কার্যকরী হয়ে উঠেছে। ওয়েব ব্রাউজারগুলি স্বয়ংক্রিয় অনুবাদ সরবরাহ করেছিল। AI দ্বারা সক্ষম করা জিনিসগুলি বলা শীতল শোনাচ্ছিল, লজ্জাজনক নয়, যদিও এটি কিছুটা অপ্রয়োজনীয় ছিল; তারপর এবং এখন প্রায় প্রতিটি প্রযুক্তি AI হিসাবে উল্লেখ করা আসলে বোনেটের নিচে গভীর শিক্ষার উপর নির্ভর করে।
২০১৭ সালে একটি গুণগত পরিবর্তন আরও কম্পিউটিং পাওয়ার এবং আরও ডেটা সরবরাহ করা পরিমাণগত সুবিধার সাথে যুক্ত হয়েছিল: নিউরনের মধ্যে সংযোগের ব্যবস্থা করার একটি নতুন উপায় ট্রান্সফরমার বলা হয়। ট্রান্সফরমারগুলি নিউরাল নেটওয়ার্কগুলিকে তাদের ইনপুটের নিদর্শনগুলি ট্র্যাক করতে সক্ষম করে, এমনকি নিদর্শনগুলির উপাদানগুলি যদি অনেক দূরে থাকে, এমন একটি উপায়ে যা তাদের ডেটাতে নির্দিষ্ট বৈশিষ্ট্যগুলিতে “মনোযোগ” প্রদান করতে সক্ষম করে।

ট্রান্সফরমারগুলি নেটওয়ার্কগুলিকে প্রসঙ্গের একটি ভাল ধারণা দেয়, যা তাদের “স্ব-পর্যবেক্ষণ শেখার” নামে একটি কৌশলের জন্য উপযুক্ত করে। মূলত, প্রশিক্ষণের সময় কিছু শব্দ এলোমেলোভাবে ফাঁকা করা হয় এবং মডেলটি সর্বাধিক সম্ভাব্য প্রার্থী পূরণ করার জন্য নিজেকে শেখায়। যেহেতু প্রশিক্ষণের ডেটাগুলিকে আগে থেকে লেবেল করতে হবে না, তাই বিলিয়ন বিলিয়ন শব্দের কাঁচা পাঠ্য ব্যবহার করে এমন মডেলগুলি প্রশিক্ষণ দেওয়া যেতে পারে যা ইন্টারনেট থেকে নেওয়া হয়েছে।
আপনার ভাষার মডেলটি লক্ষ্য করুন ট্রান্সফরমার-ভিত্তিক বড় ভাষার মডেলগুলি (এলএলএম) ২০১৯ সালে ব্যাপক মনোযোগ আকর্ষণ করতে শুরু করেছিল, যখন একটি মডেল জিপিটি-২ নামে ওপেনএআই দ্বারা প্রকাশ করা হয়েছিল, একটি স্টার্টআপ (জিপিটি জেনারেটিভ প্রি-ট্রেইন্ড ট্রান্সফরমার এর জন্য দাঁড়িয়েছে)। এই ধরনের LLMগুলি “উদীয়মান” আচরণের জন্য সক্ষম প্রমাণিত হয়েছিল যার জন্য তাদের স্পষ্টভাবে প্রশিক্ষণ দেওয়া হয়নি।
প্রচুর পরিমাণে ভাষা গ্রহণ করা শুধু তাদের সারসংক্ষেপ বা অনুবাদের মতো ভাষাগত কাজে দক্ষ করে তোলেনি, বরং জিনিসগুলিতেও — যেমন সহজ গাণিতিক এবং সফ্টওয়্যার লেখা — যা প্রশিক্ষণের ডেটায় অন্তর্নিহিত ছিল। কম আনন্দের সাথে এর অর্থ ছিল যে তারা তাদের কাছে পাঠানো ডেটার পক্ষপাতিত্ব পুনরুত্পাদন করেছে, যার অর্থ মানব সমাজের অনেক প্রচলিত কুসংস্কার তাদের আউটপুটে উপস্থিত হয়েছে।

নভেম্বর ২০২২ সালে, একটি বড় ওপেনএআই মডেল, জিপিটি-৩.৫, একটি চ্যাটবটের আকারে জনসাধারণের কাছে উপস্থাপন করা হয়েছিল। ওয়েব ব্রাউজার সহ যে কেউ একটি প্রম্পট প্রবেশ করতে পারে এবং একটি প্রতিক্রিয়া পেতে পারে। কোনো ভোক্তা পণ্য এর আগে এত দ্রুত বন্ধ হয়নি। কয়েক সপ্তাহের মধ্যে ChatGPT কলেজের প্রবন্ধ থেকে কম্পিউটার কোড তৈরি করছিল। AI আরেকটি দুর্দান্ত লিপ নিয়েছিল।
যেখানে AI-চালিত পণ্যের প্রথম গুচ্ছ স্বীকৃতির উপর ভিত্তি করে তৈরি হয়েছিল, সেখানে দ্বিতীয়টি প্রজন্মের উপর ভিত্তি করে। স্টেবল ডিফিউশন এবং ডিএএল-ইয়ের মতো গভীর-শিক্ষা মডেলগুলি, যেগুলি সেই সময়ের কাছাকাছি তাদের আত্মপ্রকাশ করেছিল, পাঠ্য প্রম্পটগুলিকে চিত্রগুলিতে পরিণত করতে ডিফিউশন নামে একটি কৌশল ব্যবহার করেছিল। অন্যান্য মডেলগুলি অবিশ্বাস্যভাবে বাস্তবসম্মত ভিডিও, বক্তৃতা বা সঙ্গীত তৈরি করতে পারে। লিপটি কেবল প্রযুক্তিগত নয়। কিছু তৈরি করা পার্থক্য তৈরি করে।

ChatGPT এবং জেমিনি (গুগল থেকে) এবং ক্লড (অ্যানথ্রপিক থেকে, পূর্বে ওপেনএআই-এ গবেষকরা দ্বারা প্রতিষ্ঠিত) এর মতো প্রতিদ্বন্দ্বীরা ঠিক যেমন অন্য গভীর-শিক্ষা সিস্টেমগুলি ঠিক করে তেমনি গণনা থেকে আউটপুট তৈরি করে। কিন্তু যেহেতু তারা অনুরোধগুলিতে নতুনত্বের সাথে সাড়া দেয় তাই তারা সত্যিই “ভাষা ব্যবহার করে” এবং “বিমূর্ততা গঠন করে” মনে হয়, যেমনটি ম্যাককার্থি আশা করেছিলেন।
এই সংক্ষিপ্তগুলির সিরিজটি দেখবে কীভাবে এই মডেলগুলি কাজ করে, তাদের ক্ষমতা কতটা বাড়তে পারে, তাদের কী নতুন ব্যবহার করা হবে, পাশাপাশি তারা কী ব্যবহার করবে না বা করা উচিত নয়।



















